QLoRA 파인튜닝 실습 ( Gemma-3-270m-it 사용)
270M 파라미터를 가진 소형 Gemma 모델인 "google/gemma-3-270m-it"을 파인 튜닝하는 과정을 다루고 있습니다.
GPU 메모리가 6G인 3060에서도 진행가능합니다.
2025.8.21 최초작성
코랩에서 포스트에서 사용한 모델보다 좀 더 큰 모델인 gemma-3-4b-it를 코랩에서 학습시켜보는 유튜브 영상도 있습니다.
270M 파라미터란?
모델 이름 "google/gemma-3-270m-it"을 보면 270m이라고 적힌 부분이 있습니다.
270M은 2억 7천만 개의 숫자(가중치)를 의미하며 각 파라미터는 모델이 학습한 "지식의 조각"입니다.
2억 7천만개가 많아보이지만 약 100조개인 사람의 뇌 뉴런 연결에 비하면 매우 작은 규모입니다.
실제 모델 파일의 크기를 따져봅니다. 실수를 저장할 때 어떤 정밀도를 사용했냐에 따라 파일 크기가 달라집니다.
기본 정밀도인 float32를 사용하면 각 파라미터당 4바이트가 필요하므로 전체 파일 크기는 약 1.08GB가 됩니다. 반정밀도인 float16을 사용하면 파라미터당 2바이트만 필요하므로 파일 크기가 약 540MB로 줄어들고, 4비트 양자화 기법을 사용하면 파라미터당 0.5바이트만 사용하여 약 135MB까지 압축할 수 있습니다. 다만 압축할수록 정확도는 약간씩 떨어질 수 있습니다.
기본 정밀도(float32): 270M × 4바이트 = 약 1.08GB
반정밀도(float16): 270M × 2바이트 = 약 540MB
4비트 양자화: 270M × 0.5바이트 = 약 135MB
다른 모델과 비교해봅니다.
| 모델명 | 파라미터 수 | 크기 (float16) | 특징 |
|---|---|---|---|
| Gemma-270M | 0.27B | ~540MB | 📱 스마트폰에서도 실행 가능 |
| Gemma-2B | 2B | ~4GB | 💻 개인용 PC GPU에서 실행 |
270M 모델은 가벼워서 실행 속도가 빠르고, 개인 컴퓨터에서도 파인튜닝이 가능하며, 실시간 응답이 가능합니다. 하지만 모델 크기가 작은 만큼 복잡한 수학 문제나 논리적 추론에는 제한이 있고, 보유한 지식의 범위가 좁으며, 창의적인 글쓰기나 예술적 창작 능력은 상대적으로 부족합니다.
Gemma-3-270m 모델과 Gemma-3-270m-it 모델의 차이
1. Gemma-3-270m : pretrained (기본 모델)에서 파인튜닝
Pretrained 모델은 이미 대량의 텍스트로 언어를 학습했지만, 특정 작업을 수행하도록 추가 훈련되지 않은 모델입니다. 이 모델은 텍스트 분류기를 만들거나 특정 분야에만 특화된 언어모델을 개발할 때 적합합니다. 예를 들어 의료 분야의 전문 용어만 다루는 모델이나, 감정 분석만 하는 분류 모델을 만들고 싶다면 이 모델을 선택하는 것이 좋습니다.
이 모델의 가장 큰 장점은 완전히 깨끗한 상태라는 점입니다. 다른 목적으로 학습된 내용이 없기 때문에 여러분이 원하는 방향으로 자유롭게 학습시킬 수 있습니다. 하지만 단점도 있습니다. 아직 특정 작업을 수행하는 방법을 모르기 때문에 여러분의 목적에 맞게 작동하도록 더 많은 데이터와 시간, 그리고 컴퓨터 성능이 필요합니다.
2. Gemma-3-270m-it : it (instruction-tuned) 모델에서 파인튜닝
Instruction-Tuned 모델은 이미 사람의 명령을 이해하고 따르는 능력이 학습된 모델입니다. 챗봇을 만들거나 질문에 답하는 시스템, 또는 사용자의 요청을 수행하는 AI 어시스턴트를 개발할 때 이 모델을 사용하면 좋습니다.
이 모델의 장점은 이미 대화하는 방법을 알고 있다는 것입니다. 따라서 비교적 적은 양의 데이터로도 빠르게 원하는 성능을 얻을 수 있고, 학습 결과도 더 안정적입니다. 하지만 이미 대화 방식으로 학습이 되어 있기 때문에, 단순한 분류 작업이나 특별한 형태의 출력이 필요한 경우에는 기존 학습 내용이 오히려 방해가 될 수 있습니다.
대화형 서비스나 질의응답 시스템을 만든다면 it 모델을, 특수한 목적의 분류기나 도메인 특화 모델을 만든다면 pretrained 모델을 선택하는 것이 효율적입니다.
본 포스팅에선 it 모델인 Gemma-3-270m-it를 사용합니다.
파인튜닝을 하는 이유는 무엇인가요?
배포된 기본 모델은 모든 사람이 사용할 수 있도록 범용적으로 만들어졌습니다. 이는 다양한 주제에 대해 일반적인 대화를 할 수 있지만, 특정 분야나 업무에 특화된 작업을 수행하기에는 한계가 있다는 뜻입니다.
의료 분야에서 사용할 AI를 만들고 싶다면, 의학 용어와 진료 상황에 맞는 응답을 해야 합니다. 하지만 범용 모델은 의학 전문 지식이 부족하거나 부정확할 수 있습니다. 만약 의료 데이터셋으로 파인튜닝하면 의료 전문 AI로 변화시킬 수 있습니다.
파인튜닝 방법
여러가지 파인 튜닝 방법이 있지만 여기에선 두가지만 살펴봅니다.
풀 파인튜닝 (Full Fine-tuning)
풀 파인튜닝은 모델의 전체 파라미터를 모두 새롭게 학습시키는 방법입니다.
새로운 데이터셋으로 모델 전체를 처음부터 다시 가르치는 과정이므로, 특정 분야에서 가장 뛰어난 성능을 얻을 수 있습니다. 의료 전문 모델이나 특정 기업의 고객 서비스 챗봇을 만들 때 가장 정확한 결과를 보여줍니다.
하지만 최소 8GB 이상의 강력한 GPU가 필요하고, 학습 시간도 몇 시간에서 며칠까지 오래 걸립니다. 클라우드 GPU 사용 시 비용도 상당히 많이 들어서 처음 파인튜닝을 시도하는 사람에게는 부담스러운 방법입니다. 처음 파인튜닝을 시도한다면 LoRA나 QLoRA 같은 효율적인 방법을 먼저 사용해보는 것을 권장합니다.
for param in model.parameters():
param.requires_grad = True # 모든 가중치 학습 가능
QLora 파인튜닝 (Quantized Low-Rank Adaptation)
QLoRA는 기존 모델을 얼려두고(고정하고) 작은 어댑터만 추가해서 학습하는 효율적인 방법입니다. 2억 7천만 개의 기존 파라미터는 전혀 건드리지 않고, 새로운 작은 모듈만 붙여서 특정 작업을 학습시킵니다.
4비트 양자화 기술을 함께 사용하면 GPU 메모리 사용량이 대폭 줄어듭니다. 풀 파인튜닝에서 16GB가 필요했다면, QLoRA는 그보다 적은 메모리의 GPU로도 학습할 수 있습니다. 물론 모델의 크기가 작은 경우가 아니면 6GB 메모리의 GPU로 학습하긴 어렵습니다.
학습 시간도 풀 파인튜닝보다 훨씬 빠르고 비용도 저렴합니다. 다만 기존 모델을 완전히 바꾸지 않기 때문에 풀 파인튜닝에 비해서는 성능이 약간 떨어질 수 있지만, 대부분의 실용적인 용도에서는 충분히 좋은 결과를 보여줍니다. 처음 파인 튜닝을 시도하는 사람에게 적당한 파인튜닝 방법입니다.
base_model.freeze() # 기존 파라미터 고정
lora_adapter = LoraLayer(rank=16) # 작은 어댑터만 학습
어떤 방법을 선택해야 할까?
처음 파인 튜닝을 시도하는 사람에게는 QLoRA를 추천합니다. GPU 메모리가 8GB 이하인 일반적인 게이밍 PC에서도 사용 가능하고, 빠른 실험과 학습이 가능하며 비용도 절약할 수 있기 때문입니다.
풀 파인튜닝은 정말 최고 성능이 필요한 상업적 프로젝트나 완전히 새로운 분야로 모델을 바꿔야 할 때만 고려하세요. 12GB 이상의 강력한 GPU와 충분한 시간, 예산이 있고 상용 서비스를 개발하는 경우에만 선택하는 것이 좋습니다. 처음 시작하는 분들은 QLoRA로 경험을 쌓은 후 필요에 따라 풀 파인튜닝을 고려해보세요.
QLora 파인 튜닝
풀 파인 튜닝 방법은 다음 링크에서 확인하세요. 본 포스팅에서는 QLora 파인 튜닝을 진행해봅니다.
https://colab.research.google.com/github/google/generative-ai-docs/blob/main/site/en/gemma/docs/core/huggingface_text_full_finetune.ipynb
miniconda를 사용하여 파이썬 개발환경을 구축해서 진행했습니다. 다음 포스트를 참고하세요.
Visual Studio Code와 Miniconda를 사용한 Python 개발 환경 만들기( Windows, Ubuntu, WSL2)
https://webnautes.kr/visual-studio-codewa-minicondareul-sayonghan-python-gaebal-hwangyeong-mandeulgi-windows-ubuntu-wsl2/
CUDA를 사용하여 PyTorch 설치하는 방법은 다음 포스트를 참고하세요.
Windows에 CUDA 사용할 수 있도록 PyTorch 설치하는 방법
https://webnautes.kr/windowse-cuda-sayonghal-su-issdorog-pytorch-seolcihaneun-bangbeob/
Ubuntu에 CUDA 사용할 수 있도록 PyTorch 설치하는 방법
https://webnautes.kr/ubuntue-cuda-sayonghal-su-issdorog-pytorch-seolcihaneun-bangbeob-2/
추가 라이브러리를 설치해야 합니다.
pip install transformers datasets accelerate evaluate trl peft bitsandbytes
윈도우에서 학습용 코드를 실행했더니 에러가 발생했습니다.
(pytorch) C:\Users\freem\OneDrive\바탕 화면\Gemma>C:/Users/freem/miniconda3/envs/pytorch/python.exe "c:/Users/freem/OneDrive/바탕 화면/Gemma/train.py"
Traceback (most recent call last):
File "C:\Users\freem\miniconda3\envs\pytorch\Lib\site-packages\markupsafe\__init__.py", line 326, in <module>
from ._speedups import escape as escape
ModuleNotFoundError: No module named 'markupsafe._speedups'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "c:\Users\freem\OneDrive\바탕 화면\Gemma\train.py", line 11, in <module>
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
File "C:\Users\freem\miniconda3\envs\pytorch\Lib\site-packages\transformers\__init__.py", line 27, in <module>
from . import dependency_versions_check
File "C:\Users\freem\miniconda3\envs\pytorch\Lib\site-packages\transformers\dependency_versions_check.py", line 16, in <module>
from .utils.versions import require_version, require_version_core
File "C:\Users\freem\miniconda3\envs\pytorch\Lib\site-packages\transformers\utils\__init__.py", line 37, in <module>
from .chat_template_utils import DocstringParsingException, TypeHintParsingException, get_json_schema
File "C:\Users\freem\miniconda3\envs\pytorch\Lib\site-packages\transformers\utils\chat_template_utils.py", line 43, in <module>
import jinja2
File "C:\Users\freem\miniconda3\envs\pytorch\Lib\site-packages\jinja2\__init__.py", line 9, in <module>
from .environment import Environment as Environment
File "C:\Users\freem\miniconda3\envs\pytorch\Lib\site-packages\jinja2\environment.py", line 15, in <module>
from markupsafe import Markup
File "C:\Users\freem\miniconda3\envs\pytorch\Lib\site-packages\markupsafe\__init__.py", line 330, in <module>
from ._native import escape as escape
ModuleNotFoundError: No module named 'markupsafe._native'
다음 패키지를 삭제했다가 다시 시작했더니 문제가 사라졌습니다.
pip uninstall markupsafe
pip install markupsafe
이번엔 다음 에러가 납니다.
Cannot access gated repo for url https://huggingface.co/google/gemma-3-270m-it/resolve/main/config.json.
Access to model google/gemma-3-270m-it is restricted. You must have access to it and be authenticated to access it. Please log in.
https://huggingface.co/google/gemma-3-270m-it 에 접속하여 사용 승인을 받아야 합니다. 로그인 한 상태에서 링크에 접속해야 승인을 받을 건지 물어보는 메시지가 보입니다.
승인을 받았다면 터미널에서 로그인을 해야 합니다.
추가로 패키지를 설치합니다.
pip install huggingface-hub
이제 로그인을 합니다.
hf auth login
다음처럼 보입니다.
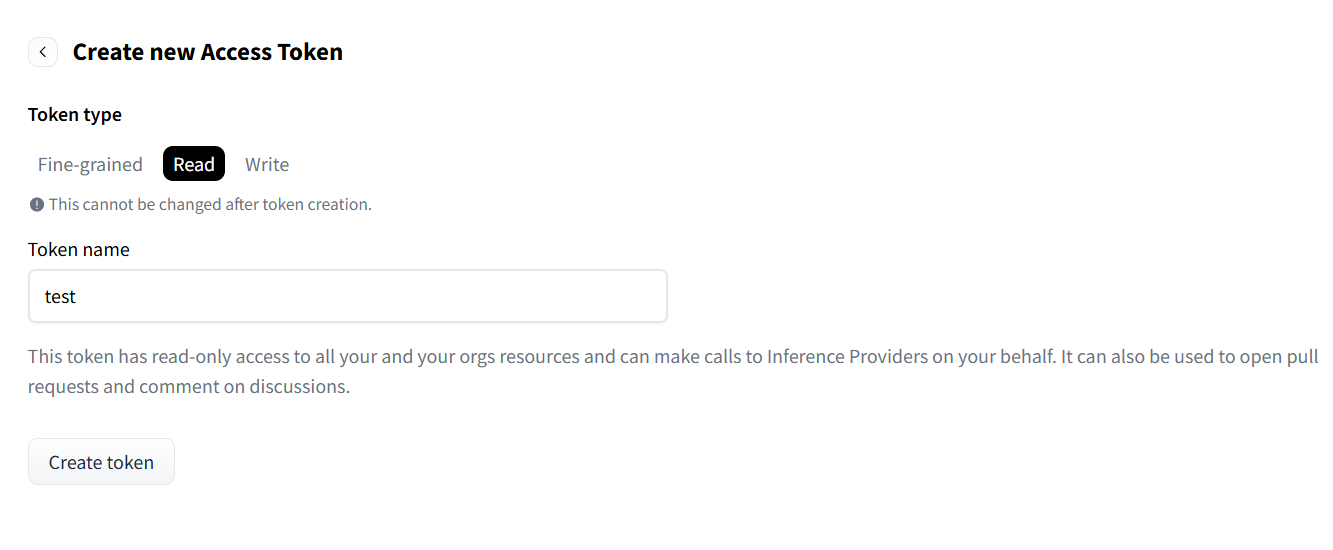
https://huggingface.co/settings/tokens 에 접속하여 다음 스크린샷 상태에서 Create token버튼을 클릭하면 생성된 토큰이 보입니다. 복사한 후 터미널 붙여넣으면 됩니다.
이제 학습용 코드를 실행해보면 문제 없이 실행됩니다.
gemma-3-270m-it를 KorQuAD 1.0 전체 데이터셋으로 QLora 파인튜닝하는데 5시간정도 걸렸습니다. 테스트한 사양은 4060 8G인 노트북입니다.
그래서 1000개 데이터만 사용하도록 수정하니 15분 정도만에 학습이 완료되고 3060 6G인 노트북에서도 학습이 가능했습니다.
train_data = process_examples(dataset['train'][:1000])
전체 데이터셋을 사용하려면 다음처럼 수정하세요.
train_data = process_examples(dataset['train'])
메모리 절약을 위해 검증 데이터셋도 사용하지 않기 때문에 accuracy나 loss 그래프도 그리지 않습니다.
270m은 너무 작은 모델이라 지금 사용한 데이터셋을 완벽히 학습하지는 못하는 듯합니다. 성능이 좋지는 않습니다.
로그
학습 로그와 추론 로그를 남겨놓습니다.
학습 로그입니다.
사용할 모델: google/gemma-3-270m-it
양자화 설정 완료 - 메모리 사용량이 약 1/4로 줄어듭니다!
모델 로딩 중... (시간이 조금 걸릴 수 있습니다)
config.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.35k/1.35k [00:00<00:00, 7.59MB/s]
model.safetensors: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 536M/536M [00:08<00:00, 66.7MB/s]
generation_config.json: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 173/173 [00:00<00:00, 888kB/s]
모델 로딩 완료!
토크나이저 로딩 중...
tokenizer_config.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.16M/1.16M [00:01<00:00, 917kB/s]
tokenizer.model: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4.69M/4.69M [00:00<00:00, 26.8MB/s]
tokenizer.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 33.4M/33.4M [00:00<00:00, 60.5MB/s]
added_tokens.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 35.0/35.0 [00:00<00:00, 264kB/s]
special_tokens_map.json: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 662/662 [00:00<00:00, 6.43MB/s]
chat_template.jinja: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.53k/1.53k [00:00<00:00, 16.6MB/s]
토크나이저 로딩 완료!
⚙️ LoRA 설정 중...
LoRA 설정 완료!
- LoRA rank: 16
- 훈련 가능한 파라미터 비율: 약 1-2%
KorQuAD 1.0 데이터셋 로딩 중...
- 훈련 데이터: 60407개
- 검증 데이터: 5774개
훈련 데이터 변환 중...
총 1000개 데이터를 배치 크기 1000로 처리 중...
배치 처리 중: 1~1000 (1000개)
진행률: 100.0% (1000개 처리 완료)
검증 데이터 변환 중...
총 100개 데이터를 배치 크기 1000로 처리 중...
배치 처리 중: 1~100 (100개)
진행률: 100.0% (100개 처리 완료)
✅ 데이터 전처리 완료!
- 최종 훈련 데이터: 1000개
- 최종 검증 데이터: 100개
================================================================================
훈련 데이터 샘플 확인
================================================================================
사용자 메시지 (앞 200자):
다음 지문을 읽고 질문에 답하세요.
지문:
1839년 바그너는 괴테의 파우스트을 처음 읽고 그 내용에 마음이 끌려 이를 소재로 해서 하나의 교향곡을 쓰려는 뜻을 갖는다. 이 시기 바그너는 1838년에 빛 독촉으로 산전수전을 다 걲은 상황이라 좌절과 실망에 가득했으며 메피스토펠레스를 만나는 파우스트의 심경에 공감했다고 한다. 또한 파리에서 아브네크의 지휘로...
어시스턴트 답변:
교향곡
================================================================================
Dataset 형식으로 변환 중...
Dataset 변환 완료! 크기: 1000
훈련 설정 중...
훈련 설정 완료!
- 총 에포크: 3
- 배치 크기: 1
- 학습률: 0.0003
- 최대 시퀀스 길이: 512
Tokenizing train dataset: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 2057.29 examples/s]
Truncating train dataset: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 176468.53 examples/s]
================================================================================
KorQuAD 1.0 데이터셋으로 QLora 파인튜닝 시작!
================================================================================
훈련 중에는 loss가 점점 줄어드는 것을 확인할 수 있습니다.
================================================================================
0%| | 0/375 [00:00<?, ?it/s]`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`.
{'train_runtime': 630.4675, 'train_samples_per_second': 4.758, 'train_steps_per_second': 0.595, 'train_loss': 2.0592766927083335, 'num_tokens': 1087536.0, 'mean_token_accuracy': 0.5702655239303906, 'epoch': 3.0}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 375/375 [10:30<00:00, 1.68s/it]
훈련 완료!
최종 모델 저장 중...
모델 저장 완료!
저장 위치: ./gemma-270m-korquad
메모리 정리 중...
학습 완료후 추론 결과입니다.
추론을 위한 샘플을 선택할때 랜덤 시드를 설정하지 않았기 때문에 실행할때마다 결과가 다릅니다.
KorQuAD 1.0 데이터셋 로딩 중...
- 훈련 데이터: 60407개
- 테스트 데이터: 5774개
train 데이터에서 랜덤하게 10개 선택 중...
선택된 train 인덱스: [818, 3081, 6440, 8077, 11348, 18122, 18140, 31207, 46443, 55199]
train 데이터 전처리 완료! 10개
test 데이터에서 랜덤하게 10개 선택 중...
선택된 test 인덱스: [480, 911, 1466, 2862, 3065, 3581, 3674, 3824, 4862, 5768]
test 데이터 전처리 완료! 10개
토크나이저 로딩 중...
토크나이저 로딩 완료!
기본 모델 로딩 중...
기본 모델 로딩 완료!
LoRA 어댑터 로딩 및 병합 중...
파인튜닝된 모델 로딩 완료!
KorQuAD 파인튜닝 모델 평가!
Train 10개 + Test 10개 샘플 테스트
================================================================================
train 10개 + test 10개 샘플 테스트 시작!
====================================================================================================
TRAIN 데이터 테스트 1/10 (전체 1/20)
================================================================================
지문:
--------------------------------------------------
1987년 화개장터에 대한 신문기사로 조영남과 함께 '화개장터'를 작사하여 큰 화제가 되었다. 소설가 활동 외에 방송인으로 자신의 이름을 내건 토크쇼《김한길과 사람들》의 진행을 비롯하여 방송활동을 했다. 1981년에 이어령의 딸 이민아와 결혼 하였고 아들 김유진을 두었으며 1986년 미국에서 이혼하고 한국으로 돌아왔다. 1992년 제14대 총선에 서울 동작구 을에 통일국민당 소속으로 출마하였으나 낙선하였다.이후 제14대 대선에 출마한 정주영의 공보특별보좌관을 맡았다. 1991년 40세에 최명길과 재혼하여 2남을 두었다. 1996년 제...
질문:
--------------------------------------------------
1998년 김대중 정부 출범시 김한길이 맡은 보직은?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
정치국민회의 전국구 의원
데이터셋 정답:
--------------------------------------------------
문화관광부 장관
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TRAIN 데이터 테스트 2/10 (전체 2/20)
================================================================================
지문:
--------------------------------------------------
1980년대 베리는 한 해에 70번에서 100번까지 계속해서 공연 활동을 했다. 여전히 솔로로 순회 공연을 돌았고, 매번 가는 길마다 동네 밴드와 협연을 하곤 했다. 1986년, 테일러 핵퍼드는 베리의 60번째 생일을 기념하여 키스 리처즈에 의해 기획된 축하 콘서트를 담은 《헤일! 헤일! 로큰롤》라는 다큐멘터리를 제작했다. 에릭 클랩턴, 에타 제임스, 줄리언 레논, 로버트 크레이, 린다 론스태트 등의 음악가가 베리와 함께 무대에 올랐다. 콘서트에서 베리는 1970년대 투어에서 그가 애용한 깁슨 ES-355과 ES-335의 럭셔리 버...
질문:
--------------------------------------------------
'헤일! 헤일! 로큰롤'은 누구에 의해 제작되었는가?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
에릭 클립턴, 에타 제임스, 줄리언 레논, 로버트 크레이, 린다 론스태트.
데이터셋 정답:
--------------------------------------------------
테일러 핵퍼드
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TRAIN 데이터 테스트 3/10 (전체 3/20)
================================================================================
지문:
--------------------------------------------------
2017년 1월 16일 서울 노원구 공릉동의 태릉국제스케이트장에서 열린 제98회 전국동계체육대회 일반부 매스스타트에 김보름이 출전했지만 선두에 한 바퀴 뒤지면 실격 당하는 규정에 따라 실격됐다. 18일 열린 1500m에서는 김보름이 2분01초70으로 결승선을 통과, 1위에 올랐다. 17일 열린 3000m에서 대회신기록(4분14초54)을 작성하며 금메달을 목에 건 김보름은 이날 1500m에서도 대회기록을 갈아치웠다. 김보름은 이주연이 보유하고 있던 대회기록(2분3초63)을 1.93초 단축했다. 노선영(28-강 원도청)도 종전 대회기록보...
질문:
--------------------------------------------------
김보름은 1500m에서 이주연이 보유하던 기록을 얼마나 단축하였는가?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
2분01초70. 김보름은 이주연이 보유하고 있던 대회기록(2분3초63)을 1.93초 단축했다. 김보름은 이주연이 보유하고 있던 대회기록(2분3초63)
데이터셋 정답:
--------------------------------------------------
1.93초
비교 결과:
--------------------------------------------------
정답이 포함되어 있습니다!
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TRAIN 데이터 테스트 4/10 (전체 4/20)
================================================================================
지문:
--------------------------------------------------
2000년 11월 베리는 동료 피아니스트 조니 존슨에 의해 법적 문제에 휘말린다. 조니는 베리와 자신이 〈No Particular Place to Go〉, 〈Sweet Little Sixteen〉, 〈Roll Over Beethoven〉를 비롯한 50곡을 공동 작곡했으나 크레디트에는 달랑 베리 혼자 뿐이라고 주장했다. 이 소송은 판사가 작곡한 시점에서 너무 오랜 시간이 지났다고 판결하면서 기각되었다. 2008년 베리는 스웨덴, 노르웨이, 핀란드, 영국, 네덜란드, 아일랜드, 스위스, 폴란드, 스페인 등의 유럽 각국에서 투어를 돌았다...
질문:
--------------------------------------------------
2000년 11년 베리와 법적 문제에 휘말린 피아니스트는 누구인가?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
조니 존슨
데이터셋 정답:
--------------------------------------------------
조니 존슨
비교 결과:
--------------------------------------------------
완전 일치! 정확한 답변입니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TRAIN 데이터 테스트 5/10 (전체 5/20)
================================================================================
지문:
--------------------------------------------------
2011년 제2 배수갑문을 겸하는 조력발전소가 완공되면서 3,000만t이었던 해수유통량이 1억6000만t으로 증대되었다. 이에 빠르게 수질이 회복되었다. 그리고 연안오염총량 관리제, 환경기초시설 운영, 산업단지 폐수 관리의 ‘시화호종합관리계획’ 또 한 시화호의 회복에 함께 이바지하였다. 2014년 9월부터 12월까지 시화호로 날아든 철새는 천연기념물 큰고니 등의 3만 마리로 20년 중 가장 많은 개체 수가 시화호 인근에 둥지를 틀었다. 이러한 변화는 시화호 인접 지역을 살기 좋은 곳으로 만들 어 지역 개발에 활기를 띠게 하였다. 이에따...
질문:
--------------------------------------------------
제2 배수갑문을 겸하는 조력발전소가 완공된 년도는?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
2011년 제2 배수갑문 겸하는 조력발전소가 완공되면서 3,000만t였던 해수유통량이 1억6000만t으로 증대되었다. 하지만 2014년 9월부터
데이터셋 정답:
--------------------------------------------------
2011년
비교 결과:
--------------------------------------------------
정답이 포함되어 있습니다!
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TRAIN 데이터 테스트 6/10 (전체 6/20)
================================================================================
지문:
--------------------------------------------------
이적 첫 해인 1976년에는 선발로 등록됐지만 혈행장애와 심장질환 등으로 인해 많은 투구 이닝을 소화할 수 없었던 탓에 뚜렷한 성적을 낼 수 없었다. 경기 도중에 심장 발작이 자주 일어나 움직일 수 없게 되면서 감독인 노무라가 조마조마 하는 경우도 자주 있었다고 한다. 하지만 제구력은 여전히 리그 최상이었기 때문에 50개 정도의 짧은 투구 수라면 충분히 전력에 도움이 될 것이라고 생각했던 노무라 감독이 구원 투수로 전향할 것을 몇 번씩이나 이야기했다. 당시에는 구원 투수의 지위가 매우 낮았기 때문에 에나쓰도 처음에는 “트레이드에 이...
질문:
--------------------------------------------------
에나쓰 유타카가 구원 투수로 전향을 결심한 해는?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
1977년 6월 경에 구원 투수로 전향을 결심했다.
데이터셋 정답:
--------------------------------------------------
1977년
비교 결과:
--------------------------------------------------
정답이 포함되어 있습니다!
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TRAIN 데이터 테스트 7/10 (전체 7/20)
================================================================================
지문:
--------------------------------------------------
강남중앙침례교회는 최진실의 유가족들이 다니는 교회였다. 조성민은 2009년 1월부터 이 교회에 출석했고 같은 해 6월에 기독교IPTV와 공동주최로 ‘기독교 어린이 야구 영성 캠프’를 기획했다. 조성민은 이 캠프에 대해 강남중앙침례교회를 협력단체로 하고 강남중앙침례교회의 전도사 4명이 참가한다고 홍보했다. 과거의 행실로 인해 부정적인 이미지를 가진 조성민이 한다는 이유로 또 상업적인 목적으로 하는 게 아니냐는 의혹 때문에 조성민의 ‘야구 영성 캠프’에 대해 기독교 내부에서 비판적인 여론이 있었다. 굳이 강남중앙침례교회와 신앙적으로든,...
질문:
--------------------------------------------------
조성민이 2009년 6월 기독교IPTV와 공동주최로 기획한 것은?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
'기독교 어린이 야구 영성 캠프'
데이터셋 정답:
--------------------------------------------------
기독교 어린이 야구 영성 캠프
비교 결과:
--------------------------------------------------
정답이 포함되어 있습니다!
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TRAIN 데이터 테스트 8/10 (전체 8/20)
================================================================================
지문:
--------------------------------------------------
1968년 6월 3일, 솔라나스는 기로디어스를 찾았으나 주말 휴가를 가 있었기에 찾을 수 없었다. 그러자 그녀는 워홀의 작업소인 팩토리를 찾아가 그에게 총 세 발을 쏘았다. 첫번째와 두번째 총알은 빗나갔으나 마지막 총알이 워홀에게 치명상을 입혔다. 그리고 같은 자리에 있던 미술평론가 마리오 아마야를 쏘았고, 워홀의 매니저 프레드 휴즈를 영거리 사격으로 쏘았으나 탄피배출 불량으로 총이 걸렸다. 솔라나스는 경찰에 자수했고, 살인, 폭행, 불법 총기소유 혐의로 기소되었다. 그녀는 편집조현병 진단을 받았고, 징역 3년형을 선고받고 정신병원...
질문:
--------------------------------------------------
밸러리 솔라나스가 워홀을 쏠 때 세 번째 총알을 빗맞은 사람은?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
프레드 휴즈를 영거리 사격으로 쏘았고, 워홀의 매니저 프레드 휴즈를 영거리 사격으로 쏘았으나 탄피배출 불량으로 총이 걸렸다.
데이터셋 정답:
--------------------------------------------------
마리오 아마야
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TRAIN 데이터 테스트 9/10 (전체 9/20)
================================================================================
지문:
--------------------------------------------------
1984년 1월 1일에 발표한 〈키타 윙〉(北ウイング)을 시작으로 나카모리 아키나는 서서히 노선에 변화를 주기 시작하였다. 주로 맑은 미성으로만 노래하기보다는 허스키하고 굵은 중저음으로 음색을 내기 시작하며 더불어 노래를 소화하는 감정처리 능력과 가창력도 점차 늘어났다. 이때에 이르러 그녀는 자신 특유의 창법인 ‘아키나 비브라토’를 개발, 곡의 대부분을 중저음으로 부르다 마지막 부분에서 압도적인 롱톤과 고음으로 시원시원한 마무리를 주는 자신만의 노래 스타일을 확실하게 개척하기에 이른다. 이어서 5월에는 데뷔 2주년을 맞아 다섯 번째...
질문:
--------------------------------------------------
나카모리 아키나가 키타 윙을 발표한 년도는?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
것으로 알려진 곡은?
데이터셋 정답:
--------------------------------------------------
1984년
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TRAIN 데이터 테스트 10/10 (전체 10/20)
================================================================================
지문:
--------------------------------------------------
하지만, 급진주의 정치 운동이 긍정적인 효과만 보였던 것은 아니었다. 급진적인 정치 운동은 자칫하면 사회적 일탈 현상을 만연하게 하는 원인이 되기도 한다. 또한 그 과정에서 겪는 피해도 크다. 일례로 중국에서 일어났던 급진적인 사회주의 정 책인 대약진운동은 대량 아사자를 속출시켰다. 오늘날에 급진적인 사상 운동이 제대로 제어되지 못할 경우 어떠한 악영향을 끼치는 지 잘 보여주는 사례이다. 급진적 자유주의화는 자유주의 경제의 기반인 자본주의를 맹신하는 결과를 만들었으며, 정치 자유화, 경제 자유화 이후 경제적 불평등 문제가 나타났다는 ...
질문:
--------------------------------------------------
중국에서 일어난 급진적인 사회주의 정책운동은?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
대약진운동
데이터셋 정답:
--------------------------------------------------
대약진운동
비교 결과:
--------------------------------------------------
완전 일치! 정확한 답변입니다.
================================================================================
============================================================
TRAIN 데이터 테스트 완료! TEST 데이터 테스트 시작!
============================================================
TEST 데이터 테스트 1/10 (전체 11/20)
================================================================================
지문:
--------------------------------------------------
할로우바디는 일렉 기타를 논할 때 잘 끼지 못하고 그렇다고 통기타인 것도 아닌 애매한 부분이 있다. 그러나 지금도 수많은 기타리스트들이 애용하고 있고, 그 고유의 울림으로 가장 자연스러운 소리가 나는 일렉기타라고 평가받고 있다. 그렇기에 재즈나 블루스 등에 주로 쓰이고 퓨전이나 모던락, 모델에 따라서 하드락까지도 두루 쓰인다. 또한 F홀, 둥글고 곡선이 두드러지는 바디, 곱상한 색상 등으로 외관상 고급스러운 느낌이 들기도 한다. 할로우바디는 두가지 종류로 나뉜다. 세미할로우바디와 풀할로우바디. 세미할로우는 어느 정도 기존 솔리드바디...
질문:
--------------------------------------------------
할로우바디 기타는 몇 가지 종류로 나뉘는가?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
세미할로우바디, 풀할로우바디.
데이터셋 정답:
--------------------------------------------------
두가지
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TEST 데이터 테스트 2/10 (전체 12/20)
================================================================================
지문:
--------------------------------------------------
그해 9월 평양부윤에 임명되었으나 정몽주 등은 그를 제거할 목적으로 사간원과 사헌부의 간관들을 사주하여 그가 "가풍(家風)이 부정(不正)하고, 파계(派系)가 불명함에도 큰 벼슬을 받아 조정을 어지럽히고 있다"라고 탄핵케 하여 봉화로 유배당하였다. 정몽주가 정도전을 탄핵한 실제 목적은 이성계를 제거하기 위한 것이었다. 그러나 정몽주의 탄핵 내용을 접한 그는 정몽주에게 극심한 반감을 품게 된다. 이어 나주로 배소가 옮겨졌으며 두 아들은 삭탈관직당해 평민이 되었다. 이때 정몽주는 김진양을 사주하여 사죄로 다스릴 것을 상소하여 그를 처형하...
질문:
--------------------------------------------------
평양부윤에 임명된 정도전을 제거하려했던 정몽주가 유배된 곳은?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
사간원과 사헌부의 간관들을 사주하여 그가 "가풍(家風)이 부정(不正)하고, 파계(派)가 불명함에도 큰 벼슬을 받아 조정을 어지럽히고 있다"라고 탄핵케 하여 봉화로 유
데이터셋 정답:
--------------------------------------------------
봉화
비교 결과:
--------------------------------------------------
정답이 포함되어 있습니다!
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TEST 데이터 테스트 3/10 (전체 13/20)
================================================================================
지문:
--------------------------------------------------
늙은 쇼와 천황은 건강이 악화되기 전까지 아이치현 하즈(幡豆)와 소노다의 별장에서 생활했다. 운동 경기, 시 낭송회, 나무심기 행사 등에 참관하는 횟수나 외국 사절을 맞이하는 일도 점점 줄었다. 나카소네 야스히로는 쇼와 천황이 옥음방송으로 항복을 선언한지 40년이 지난 1985년 8월 15일에 현직 총리로서는 최초로 A급 전범들이 합사된 야스쿠니 신사를 공식 참배해 대한민국과 중화인민공화국을 비롯한 주변국들로부터 비난을 받았다. 나카소네는 1987년 10월 30일에 사직했고, 이어 다케시타 노보루가 총리가 됐다. 한편 쇼와 천황은 ...
질문:
--------------------------------------------------
현직 총리 최초로 야스쿠니 신사를 공식 참배한 사람은?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
0년대 초반에 시작되었고, 2000년대 초반에 대두되기 시작했다. 그러나 쇼와 천황의 폐하분
데이터셋 정답:
--------------------------------------------------
나카소네 야스히로
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TEST 데이터 테스트 4/10 (전체 14/20)
================================================================================
지문:
--------------------------------------------------
당(唐),송(宋)시대에는 개력이 빈번하게 일어났지만, 역법의 근본적인 개혁은 일어나지 않았다. 그런데 원나라 초기에 제작된 수시력(授時曆)이 개편되면서 명나라가 망할 때까지 사용되었다. 이는 수시력이 매우 뛰어난 역법이었기 때문이었고, 또 명나라의 역법제작 기술이 수시력을 능가하지 못하였기 때문이다. 수시력은 원나라 세조(世祖) 쿠빌라이 칸(1215~1294)이 통일 직후에 왕순(王恂)과 곽수경(郭守敬)에게 개력을 명령한 것을 계기로 만들어졌다. 수시력은 충실한 관측을 통해서 천문 상수들을 다시 바로잡았고, 새로운 천문기계를 많이 ...
질문:
--------------------------------------------------
수시력은 누가 왕순과 곽수경에게 개력을 명령한 것을 계기로 만들어졌나요?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
1215~1294.
데이터셋 정답:
--------------------------------------------------
쿠빌라이 칸
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TEST 데이터 테스트 5/10 (전체 15/20)
================================================================================
지문:
--------------------------------------------------
2016년 9월 4일 중동 지역에서 갤럭시 S7 엣지가 폭발하는 사건이 발생했다. 이는 갤럭시 노트 7 폭발 사건과 관련이 있다고 추측되고 있으나, 삼성전자 측에서는 갤럭시 S7, 갤럭시 S7 엣지는 안전상의 문제가 없다고 해명하였으나, 폭발 사고가 갤럭시 S7 엣지 출시 이후 6개월 정도가 지난 후이며 판매량 또한 7000만대가량이 넘게 팔린 후에 처음 일어난 것을 생각하면 폭발한 기기들이 불량인 제품이고 모든 제품의 결함이라고 보기는 어렵다. 실제로 모든 제품이 결함이 있는 갤럭시 노트 7 은 겨우 출시 18일만이며 판매량이 20...
질문:
--------------------------------------------------
폭발 사고는 출시 이후 몇개월 정도가 지났을때 발생했나?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
6개월
데이터셋 정답:
--------------------------------------------------
6개월
비교 결과:
--------------------------------------------------
완전 일치! 정확한 답변입니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TEST 데이터 테스트 6/10 (전체 16/20)
================================================================================
지문:
--------------------------------------------------
2005년 9월 13일 푸시캣 돌스의 첫 번째 정규 음반 PCD가 발매됐다. 이 앨범은 그들이 활동했던 댄스팀 스타일의 댄스팝 음악들과, 트리뷰트, 커버곡들로 구성되어 있다. 이 앨범은 뉴질랜드에서 1위를 차지했고, 캐나다, 네덜란드, 미국에서 TOP 5 에 이름을 올렸으며, 영국, 오스트리아, 독일, 스위스, 아일랜드에서 10위까지 올라갔다. PCD는 전 세계적으로 900만 장 이상의 판매고를 올렸다. 첫 싱글 'Don't Cha'는 영국, 오스트레일리아, 캐나다 등의 나라에서 1위에 올랐고, 빌보드 핫 100 차트 2위에 올랐다....
질문:
--------------------------------------------------
푸시캣 돌스의 첫 정규 음반이 전세계에서 팔린 갯수는?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
900만 장!
데이터셋 정답:
--------------------------------------------------
900만 장
비교 결과:
--------------------------------------------------
정답이 포함되어 있습니다!
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TEST 데이터 테스트 7/10 (전체 17/20)
================================================================================
지문:
--------------------------------------------------
중국정부는 중국 본토 전역에 있어서 실효적 지배를 확립하고, 625전쟁에 참전한 후, 1954년에 소비에트연방의 공산권의 선례를 참조하여 최초의 헌법(54년헌법)을 제정하는 등, 소비에트연방법(대륙법계에 속한다)을 계수받은 법제도의 정비를 진행하였다. 그러나, 1957년 6월의 반우파 투쟁을 시작으로 1977년 8월의 문화대혁명의 종결에 이르기까지의 시기에는 “프롤레타리아독재”의 이념에서 도출되는 “중국공산당의 국가에 대한 우위”가 강조되어, 법질서보다도 중국공산당의 정책이 우선되었다. 1978년 3월에는 세 번째의 헌법(78년 헌...
질문:
--------------------------------------------------
중국이 헌법을 제정할 때 참고하였던 나라는 무엇인가?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
프롤레타리아 독재
데이터셋 정답:
--------------------------------------------------
소비에트연방
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TEST 데이터 테스트 8/10 (전체 18/20)
================================================================================
지문:
--------------------------------------------------
미국 텔레비전 시스템 위원회(National Television System Committee)는 미국 연방 통신 위원회(FCC)에서 미국 내 아날로그 텔레비전 방송사들 사이의 문제점을 해결하고자 1940년에 설립한 단체이다. NTSC에서는 1941년 3월에 흑백 텔레비전을 위한 기술 표준을 제정하였다. 이것은 1941년에 미국 라디오 생산업체 협회(Radio Manufactures Association)에서 제안한 441 라인을 사용하는 기안을 기반으로 하여 제정된 것이다. 그 뒤 잔류 측파대 (VSB - Vestigial Sid...
질문:
--------------------------------------------------
미국 텔레비전 시스템 위원회가 설립된 해는?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
1940년
데이터셋 정답:
--------------------------------------------------
1940년
비교 결과:
--------------------------------------------------
완전 일치! 정확한 답변입니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TEST 데이터 테스트 9/10 (전체 19/20)
================================================================================
지문:
--------------------------------------------------
2009년 1월 인터넷 논객 미네르바의 처벌 수위가 심하다고 지적하였다. 그는 실정법에 위반되면 처벌하는 형식적 법치주의는 국민을 억압하는 독재의 유물이며 우리는 사회적 정의에 부합여부를 가려서 처벌을 정하는 실질적 법치주의 시대에 살고 있다고 주장하였다. 한두 가지 허위 사실이 있다고 해서 곧바로 처벌하는 건 실질적 법치주의에 반한다며 인터넷 논객 미네르바 처벌에 대한 이명박정부의 태도에 대한 비판적 시각을 제시하였다. 이에 1월 13일 한나라당의 홍준표는 원내대책회의에서 어느 야당 총재를 지칭하며 박씨 사건은 형식적 또는 실질적...
질문:
--------------------------------------------------
2009년 이회창은 인터넷 논객 누구의 처벌 수위가 심하다고 지적하였는가?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
실정법에 위반되면 처벌하는 형식적 법치주의는 국민을 억압하는 독재의 유물이며 우리는 사회적 정의에 부합여부를 가려서 처벌을 정하는 실질적 법치주의 시대에 살고 있다고 주장하였다. 한두 가지 허위 사실
데이터셋 정답:
--------------------------------------------------
미네르바
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
---------------------------------------- 다음 테스트 ----------------------------------------
TEST 데이터 테스트 10/10 (전체 20/20)
================================================================================
지문:
--------------------------------------------------
2012년 8월 18일 선덜랜드와의 프리미어리그 경기에서 교체 출전으로 데뷔했으며 9월 26일 코번트리 시티와의 리그 컵 경기에서 팀에서의 첫 골을 넣었다. 프리미어리그에서의 첫 골은 웨스트 햄을 상대로 넣었다. 이 경기에서 월컷의 골을 어시스트하기도 했다. 그의 UEFA 챔피언스리그 데뷔골은 11월 6일 샬케 04와의 경기에서 기록했다. 그가 계속해서 좋은 폼을 유지하고 멋진 활약을 보여줬기에, 아스널 팬들은 비틀즈가 부른 "Hey Jude"의 한 소절을 따와서 지루의 응원가를 만들어주었고 지루만을 위한 이 응원가는 에미레이트 스...
질문:
--------------------------------------------------
올리비에 지루가 프리미어리그에서 첫 골을 넣은 상대팀은?
모델 답변 생성 중...
The following generation flags are not valid and may be ignored: ['top_p', 'top_k']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
모델이 생성한 답변:
--------------------------------------------------
9월 26일 샬케 04
데이터셋 정답:
--------------------------------------------------
웨스트 햄
비교 결과:
--------------------------------------------------
정답과 다르지만 관련된 내용일 수 있습니다.
================================================================================
테스트 완료!
====================================================================================================
최종 통계
====================================================================================================
전체 결과 (20개 샘플)
--------------------------------------------------
완전 일치: 4개 (20.0%)
정답 포함: 6개 (30.0%)
다른 답변: 10개 (50.0%)
TRAIN 데이터 결과 (10개 샘플)
--------------------------------------------------
완전 일치: 2개 (20.0%)
정답 포함: 4개 (40.0%)
다른 답변: 4개 (40.0%)
TEST 데이터 결과 (10개 샘플)
--------------------------------------------------
완전 일치: 2개 (20.0%)
정답 포함: 2개 (20.0%)
다른 답변: 6개 (60.0%)
====================================================================================================
정확도 요약
----------------------------------------------------------------------------------------------------
전체 - 엄격한 정확도: 20.0% | 관대한 정확도: 50.0%
TRAIN - 엄격한 정확도: 20.0% | 관대한 정확도: 60.0%
TEST - 엄격한 정확도: 20.0% | 관대한 정확도: 40.0%
====================================================================================================
결과 해석:
완전 일치: 모델이 정확히 같은 답변을 생성
정답 포함: 모델 답변에 정답이 포함됨
다른 답변: 정답과 다르지만 맥락상 맞을 수 있음
TRAIN vs TEST 성능 비교를 통해 과적합 여부 확인 가능
====================================================================================================
성능 분석:
괜찮은 성능입니다!
Train vs Test 성능 차이: 20.0%
약간의 과적합이 있을 수 있습니다.
메모리 정리 중...
메모리 정리 완료!
코드
코드는 학습용 코드와 추론 및 성능 평가용 코드 두가지로 구성됩니다.
학습용 코드입니다.
"""
KorQuAD 1.0 데이터셋을 사용한 Gemma-270M 모델 QLora 파인튜닝
- KorQuAD: 한국어 질문-답변 데이터셋 (Stanford Question Answering Dataset의 한국어 버전)
- QLora: 4비트 양자화를 사용한 효율적인 파인튜닝 방법
- Gemma-270M: Google에서 개발한 소형 언어모델
"""
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig
from trl import SFTTrainer, SFTConfig
from datasets import load_dataset
import pickle
# =============================================================================
# 2. 모델과 토크나이저 설정
# =============================================================================
# 사용할 모델의 이름 (허깅페이스 모델 허브에서 가져옴)
model_id = "google/gemma-3-270m-it" # 270M 파라미터를 가진 소형 Gemma 모델
# model_id = "google/gemma-3-4b-it"
output_path = "./gemma-270m-korquad"
# output_path = "./gemma-4b-korquad"
print(f"사용할 모델: {model_id}")
# 4비트 양자화 설정 (메모리 사용량을 줄이기 위한 설정)
# 양자화: 32비트 숫자를 4비트로 압축하여 메모리를 절약하는 기술
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 4비트로 모델 로드
bnb_4bit_use_double_quant=True, # 이중 양자화 사용 (더 정확함)
bnb_4bit_quant_type="nf4", # 양자화 타입 (NormalFloat4)
bnb_4bit_compute_dtype=torch.float16, # 계산할 때 사용할 데이터 타입
bnb_4bit_quant_storage=torch.uint8, # 저장할 때 사용할 데이터 타입
)
print("양자화 설정 완료 - 메모리 사용량이 약 1/4로 줄어듭니다!")
# 모델 로드 (GPU 메모리에 모델을 불러옴)
print("모델 로딩 중... (시간이 조금 걸릴 수 있습니다)")
model = AutoModelForCausalLM.from_pretrained(
model_id, # 사용할 모델 이름
quantization_config=bnb_config, # 위에서 설정한 양자화 설정 적용
device_map="auto", # GPU/CPU 자동 배치
torch_dtype=torch.float16, # 16비트 부동소수점 사용 (메모리 절약)
attn_implementation="eager", # 어텐션 계산 방식
low_cpu_mem_usage=True, # 추가
)
print("모델 로딩 완료!")
# 토크나이저 로드 (텍스트를 숫자로 변환하는 도구)
print("토크나이저 로딩 중...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 토크나이저 설정
tokenizer.pad_token = tokenizer.eos_token # 패딩 토큰을 문장 종료 토큰으로 설정
tokenizer.padding_side = "right" # 오른쪽에 패딩 추가
print("토크나이저 로딩 완료!")
# =============================================================================
# 3. LoRA (Low-Rank Adaptation) 설정
# =============================================================================
# LoRA: 전체 모델을 훈련하는 대신 작은 어댑터만 훈련하는 효율적인 방법
print("⚙️ LoRA 설정 중...")
lora_config = LoraConfig(
r=16, # LoRA rank (낮을수록 파라미터 적음, 높을수록 표현력 좋음)
lora_alpha=32, # LoRA scaling parameter (보통 rank의 2배)
lora_dropout=0.05, # 드롭아웃 비율 (과적합 방지)
bias="none", # bias 파라미터 훈련 안함
task_type="CAUSAL_LM", # 인과적 언어모델 (다음 단어 예측)
# 어떤 레이어에 LoRA를 적용할지 지정
target_modules=["q_proj", "v_proj"],
# 반드시 저장해야 할 모듈들 (토큰 임베딩과 출력 레이어)
modules_to_save=["lm_head"]
)
print("LoRA 설정 완료!")
print(f" - LoRA rank: {lora_config.r}")
print(f" - 훈련 가능한 파라미터 비율: 약 1-2%")
# =============================================================================
# 4. KorQuAD 1.0 데이터셋 로드 및 전처리
# =============================================================================
def load_and_process_korquad():
"""
KorQuAD 1.0 데이터셋을 로드하고 QA 형식으로 변환 (속도 최적화)
"""
print("KorQuAD 1.0 데이터셋 로딩 중...")
dataset = load_dataset("squad_kor_v1")
print(f" - 훈련 데이터: {len(dataset['train'])}개")
print(f" - 검증 데이터: {len(dataset['validation'])}개")
def process_examples(examples):
"""
KorQuAD 데이터를 배치 단위로 처리하여 메모리 효율성 향상
"""
processed_data = []
batch_size = 1000 # 한 번에 처리할 데이터 개수
total_examples = len(examples['question'])
print(f"총 {total_examples}개 데이터를 배치 크기 {batch_size}로 처리 중...")
for batch_start in range(0, total_examples, batch_size):
batch_end = min(batch_start + batch_size, total_examples)
batch_data = []
print(f" 배치 처리 중: {batch_start+1}~{batch_end} ({batch_end-batch_start}개)")
for i in range(batch_start, batch_end):
context = examples['context'][i]
question = examples['question'][i]
# 답변이 있는 경우만 처리
if examples['answers'][i]['text']:
answer = examples['answers'][i]['text'][0]
# 컨텍스트 길이 제한 (메모리 및 속도 최적화)
if len(context) > 800:
# 답변이 포함된 부분을 우선적으로 유지
answer_start = examples['answers'][i]['answer_start'][0] if examples['answers'][i]['answer_start'] else 0
# 답변 주변 컨텍스트 유지
start_pos = max(0, answer_start - 300)
end_pos = min(len(context), start_pos + 800)
context = context[start_pos:end_pos]
if start_pos > 0:
context = "..." + context
if end_pos < len(examples['context'][i]):
context = context + "..."
user_message = f"다음 지문을 읽고 질문에 답하세요.\n\n지문:\n{context}\n\n질문: {question}"
batch_data.append({
"messages": [
{"role": "user", "content": user_message},
{"role": "assistant", "content": answer}
]
})
# 배치 데이터를 전체 리스트에 추가
processed_data.extend(batch_data)
# 메모리 정리 (선택적)
del batch_data
# 진행률 표시
progress = (batch_end / total_examples) * 100
print(f" 진행률: {progress:.1f}% ({len(processed_data)}개 처리 완료)")
return processed_data
print("훈련 데이터 변환 중...")
train_data = process_examples(dataset['train'][:1000])
print("검증 데이터 변환 중...")
validation_data = process_examples(dataset['validation'][:100])
# 검증 데이터 저장
with open('./korquad_validation_data.pkl', 'wb') as f:
pickle.dump(validation_data, f)
print("✅ 데이터 전처리 완료!")
print(f" - 최종 훈련 데이터: {len(train_data)}개")
print(f" - 최종 검증 데이터: {len(validation_data)}개")
return train_data, validation_data
# 데이터셋 처리 실행
train_data, validation_data = load_and_process_korquad()
# 훈련 데이터 샘플 확인 (어떤 형태인지 보여주기)
print("\n" + "="*80)
print(" 훈련 데이터 샘플 확인")
print("="*80)
sample = train_data[0]
print(" 사용자 메시지 (앞 200자):")
print(sample['messages'][0]['content'][:200] + "...")
print("\n 어시스턴트 답변:")
print(sample['messages'][1]['content'])
print("="*80)
# 허깅페이스 Dataset 형식으로 변환 (SFTTrainer가 요구하는 형식)
from datasets import Dataset
print("Dataset 형식으로 변환 중...")
# 메시지 부분만 추출하여 Dataset 생성
train_dataset = Dataset.from_list([{"messages": item["messages"]} for item in train_data])
print(f" Dataset 변환 완료! 크기: {len(train_dataset)}")
# =============================================================================
# 5. 훈련 설정 (Training Configuration)
# =============================================================================
print("\n 훈련 설정 중...")
# 8GB GPU 전용 초경량 설정
training_args = SFTConfig(
# 출력 및 저장 설정
output_dir= output_path,
# 메모리 최적화 - 가장 중요!
per_device_train_batch_size=1, # 4 → 1 (필수!)
gradient_accumulation_steps=8, # 2 → 8 (실제 배치=1*8=8 유지)
# 메모리 절약 기법들
gradient_checkpointing=True, # False → True (메모리 우선)
dataloader_pin_memory=False, # True → False (CPU 메모리 절약)
# 시퀀스 길이 대폭 축소
max_length=512,
# 정밀도 최적화
fp16=True, # 유지
bf16=False, # fp16과 동시 사용 금지
# 옵티마이저 최적화
optim="adafactor", # adamw_torch → adafactor (메모리 절약)
# 에포크 줄이기 (메모리 안정성)
num_train_epochs=3,
# 평가 완전 비활성화 (메모리 절약)
eval_strategy="no", # 평가 완전 비활성화
prediction_loss_only=True, # 유지
# 로깅 최소화
logging_steps=500, # 100 → 500
save_strategy="epoch", # 유지
save_total_limit=1, # 2 → 1 (체크포인트 1개만)
# 학습률 (메모리와 무관하지만 조정)
learning_rate=3e-4, # 5e-4 → 3e-4
# 추가 메모리 절약 옵션들
remove_unused_columns=True, # 유지
report_to="none", # 유지
# 안정성 설정
max_grad_norm=1.0, # 유지
warmup_steps=100, # 500 → 100
lr_scheduler_type="linear", # 유지
# 메모리 관리 강화
torch_empty_cache_steps=50, # 50스텝마다 캐시 정리
)
print("훈련 설정 완료!")
print(f" - 총 에포크: {training_args.num_train_epochs}")
print(f" - 배치 크기: {training_args.per_device_train_batch_size}")
print(f" - 학습률: {training_args.learning_rate}")
print(f" - 최대 시퀀스 길이: {training_args.max_length}") # max_seq_length → max_length
# =============================================================================
# 트레이너 설정 및 훈련 실행
# =============================================================================
# SFTTrainer: Supervised Fine-Tuning을 담당하는 클래스
trainer = SFTTrainer(
model=model, # 훈련할 모델
args=training_args, # 위에서 설정한 훈련 설정
train_dataset=train_dataset, # 훈련 데이터
peft_config=lora_config, # LoRA 설정
processing_class=tokenizer, # 토크나이저
)
# 실제 훈련 시작
print("\n" + "="*80)
print("KorQuAD 1.0 데이터셋으로 QLora 파인튜닝 시작!")
print("="*80)
# 훈련 실행 (시간이 오래 걸림)
trainer.train()
print("\n훈련 완료!")
print("최종 모델 저장 중...")
trainer.save_model()
print("모델 저장 완료!")
print(f"저장 위치: {training_args.output_dir}")
# 메모리 정리 (다음 단계를 위해)
print("\n메모리 정리 중...")
del model # 모델 객체 삭제
del trainer # 트레이너 객체 삭제
torch.cuda.empty_cache() # GPU 메모리 비우기
이제 추론 및 성능 평가를 진행합니다.
"""
파인튜닝된 Gemma-270M 모델로 KorQuAD 추론 및 성능 평가 (train 10개 + test 10개 샘플 테스트)
- 훈련된 모델을 로드하여 실제 질문에 답변
- KorQuAD train 데이터셋에서 10개, test 데이터셋에서 10개를 랜덤 선택하여 테스트
- 총 20개 샘플 테스트 및 통계 출력
"""
# =============================================================================
# 1. 라이브러리 임포트 및 초기 설정
# =============================================================================
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
from datasets import load_dataset
import random
from difflib import SequenceMatcher
import re
from transformers import LogitsProcessor, LogitsProcessorList
class NanInfClamp(LogitsProcessor):
def __call__(self, input_ids, scores):
# NaN/Inf → 큰 음수/양수로 치환 (샘플링 분포 유효화)
return torch.nan_to_num(scores, nan=-1e9, posinf=1e9, neginf=-1e9)
# =============================================================================
# 2. KorQuAD train/test 데이터셋 로드 및 전처리
# =============================================================================
def load_korquad_data():
"""
KorQuAD 1.0 train/test 데이터셋을 로드하고 전처리
"""
print("KorQuAD 1.0 데이터셋 로딩 중...")
dataset = load_dataset("squad_kor_v1")
train_dataset = dataset['train']
test_dataset = dataset['validation'] # KorQuAD의 validation이 실제 test 데이터
print(f" - 훈련 데이터: {len(train_dataset)}개")
print(f" - 테스트 데이터: {len(test_dataset)}개")
def process_examples(examples, dataset_type, max_samples=10):
"""
KorQuAD 데이터를 처리
"""
processed_data = []
print(f"{dataset_type} 데이터 {max_samples}개 처리 중...")
for i in range(min(max_samples, len(examples))):
context = examples[i]['context']
question = examples[i]['question']
# 답변이 있는 경우만 처리
if examples[i]['answers']['text']:
answer = examples[i]['answers']['text'][0]
# 컨텍스트 길이 제한 (메모리 및 속도 최적화)
if len(context) > 800:
# 답변이 포함된 부분을 우선적으로 유지
answer_start = examples[i]['answers']['answer_start'][0] if examples[i]['answers']['answer_start'] else 0
# 답변 주변 컨텍스트 유지
start_pos = max(0, answer_start - 300)
end_pos = min(len(context), start_pos + 800)
context = context[start_pos:end_pos]
if start_pos > 0:
context = "..." + context
if end_pos < len(examples[i]['context']):
context = context + "..."
# 사용자 메시지 구성
user_message = f"다음 지문을 읽고 질문에 답하세요.\n\n지문:\n{context}\n\n질문: {question}"
processed_data.append({
"context": context,
"question": question,
"answer": answer,
"user_message": user_message,
"dataset_type": dataset_type
})
print(f"{dataset_type} 데이터 전처리 완료! {len(processed_data)}개")
return processed_data
# train 데이터에서 10개 처리
train_data = process_examples(train_dataset, "train", max_samples=10)
# test 데이터에서 10개 처리
test_data = process_examples(test_dataset, "test", max_samples=10)
return train_data, test_data
# 데이터 로드
train_data, test_data = load_korquad_data()
# =============================================================================
# 3. 모델 및 토크나이저 로드
# =============================================================================
# 파일 경로 설정
base_model_id = "google/gemma-3-270m-it"
adapter_path = "./gemma-270m-korquad"
print("\n토크나이저 로딩 중...")
# 토크나이저 로드
tokenizer = AutoTokenizer.from_pretrained(base_model_id)
tokenizer.pad_token = tokenizer.eos_token
print("토크나이저 로딩 완료!")
print("\n기본 모델 로딩 중...")
import torch._dynamo
torch._dynamo.config.suppress_errors = True
# GPU/CPU마다 안전한 dtype 선택
if torch.cuda.is_available():
major, _ = torch.cuda.get_device_capability(0)
# Ampere(8.x)+이면 bfloat16, 아니면 float16
safe_dtype = torch.bfloat16 if major >= 8 else torch.float16
else:
# CPU면 fp32가 안전
safe_dtype = torch.float32
base_model = AutoModelForCausalLM.from_pretrained(
base_model_id,
torch_dtype=safe_dtype, # ← 안전한 dtype
device_map="auto",
low_cpu_mem_usage=True,
attn_implementation="eager",
)
# pad/eos 명시
base_model.config.pad_token_id = tokenizer.eos_token_id
base_model.config.eos_token_id = tokenizer.eos_token_id
base_model.eval()
print("기본 모델 로딩 완료!")
print("\nLoRA 어댑터 로딩 및 병합 중...")
try:
# 훈련된 LoRA 어댑터 로드
model = PeftModel.from_pretrained(base_model, adapter_path)
# 어댑터를 기본 모델에 병합
model = model.merge_and_unload()
# eval 모드 설정
model.eval()
print("파인튜닝된 모델 로딩 완료!")
except Exception as e:
print(f"어댑터 로딩 실패: {e}")
print(" 먼저 파인튜닝 코드를 실행해주세요.")
exit()
# =============================================================================
# 4. 답변 생성 함수
# =============================================================================
def generate_answer(context, question, max_new_tokens=64):
"""
KorQuAD fine-tuned Gemma 추론 (출력 후처리 포함)
"""
prompt = (
"다음 지문을 읽고 질문에 답하세요.\n\n"
f"지문:\n{context}\n\n"
f"질문: {question}\n"
f"답변:" # <- 명시적으로 답변 시작 토큰 유도
)
inputs = tokenizer(
prompt,
return_tensors="pt",
truncation=True,
max_length=512,
add_special_tokens=True,
padding=False
).to(model.device)
processors = LogitsProcessorList([NanInfClamp()])
with torch.no_grad():
try:
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=max_new_tokens,
num_beams=4,
do_sample=False,
repetition_penalty=1.05,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
logits_processor=processors,
)
except Exception as e:
print(f"빔서치 실패: {e} → 샘플링 폴백 시도")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=max_new_tokens,
do_sample=True,
temperature=0.7,
top_p=0.9,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
logits_processor=processors,
)
# 전체 출력 디코딩
full_output = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 프롬프트 제외 → 답변 부분만 추출
generated_text = full_output[len(prompt):].strip()
# 여러 줄 있으면 첫 줄만 사용
if "\n" in generated_text:
generated_text = generated_text.split("\n")[0].strip()
# 혹시 '답변:' 토큰이 중복으로 들어오면 제거
generated_text = re.sub(r"^답변[::]?\s*", "", generated_text)
if not generated_text:
generated_text = "답변을 생성하지 못했습니다."
return generated_text
# =============================================================================
# 5. train/test 데이터셋 평가 함수
# =============================================================================
def test_train_test_samples():
"""
train 데이터 10개 + test 데이터 10개 총 20개 샘플 테스트
"""
print("\ntrain 10개 + test 10개 샘플 테스트 시작!")
print("="*100)
# 통계 변수 초기화
total_exact_matches = 0
total_contains_answers = 0
total_different_answers = 0
# train/test별 통계
train_exact_matches = 0
train_contains_answers = 0
train_different_answers = 0
test_exact_matches = 0
test_contains_answers = 0
test_different_answers = 0
# train 데이터 10개 + test 데이터 10개 합치기
all_samples = train_data + test_data
for i, sample in enumerate(all_samples):
dataset_type = sample['dataset_type']
sample_num = (i % 10) + 1 # 각 데이터셋 내에서의 샘플 번호
print(f"\n{dataset_type.upper()} 데이터 테스트 {sample_num}/10 (전체 {i+1}/20)")
print("="*80)
# 데이터 추출
context = sample['context']
question = sample['question']
actual_answer = sample['answer']
print("지문:")
print("-"*50)
# 지문이 길면 처음 300자만 표시
display_context = context[:300] + "..." if len(context) > 300 else context
print(display_context)
print("\n질문:")
print("-"*50)
print(question)
print("\n모델 답변 생성 중...")
# 모델로 답변 생성
predicted_answer = generate_answer(context, question)
print("\n모델이 생성한 답변:")
print("-"*50)
print(predicted_answer)
print("\n데이터셋 정답:")
print("-"*50)
print(actual_answer)
# 간단한 비교
exact_match = predicted_answer.strip().lower() == actual_answer.strip().lower()
contains_answer = actual_answer.strip().lower() in predicted_answer.strip().lower()
print("\n비교 결과:")
print("-"*50)
if exact_match:
print("완전 일치! 정확한 답변입니다.")
total_exact_matches += 1
if dataset_type == "train":
train_exact_matches += 1
else:
test_exact_matches += 1
elif contains_answer:
print("정답이 포함되어 있습니다!")
total_contains_answers += 1
if dataset_type == "train":
train_contains_answers += 1
else:
test_contains_answers += 1
else:
print("정답과 다르지만 관련된 내용일 수 있습니다.")
total_different_answers += 1
if dataset_type == "train":
train_different_answers += 1
else:
test_different_answers += 1
print("="*80)
# train과 test 사이에 구분선 추가
if i == 9: # train 데이터 10개 완료 후
print("\n" + "=" * 60)
print(" TRAIN 데이터 테스트 완료! TEST 데이터 테스트 시작!")
print("=" * 60)
elif i < 19: # 마지막이 아니면
print("\n" + "-" * 40 + " 다음 테스트 " + "-" * 40)
# 통계 반환
return {
"total": {
"exact_matches": total_exact_matches,
"contains_answers": total_contains_answers,
"different_answers": total_different_answers
},
"train": {
"exact_matches": train_exact_matches,
"contains_answers": train_contains_answers,
"different_answers": train_different_answers
},
"test": {
"exact_matches": test_exact_matches,
"contains_answers": test_contains_answers,
"different_answers": test_different_answers
}
}
# =============================================================================
# 6. 메인 실행
# =============================================================================
if __name__ == "__main__":
print("\nKorQuAD 파인튜닝 모델 평가!")
print("Train 10개 + Test 10개 샘플 테스트")
print("="*80)
# 평가 실행
results = test_train_test_samples()
print("\n테스트 완료!")
print("="*100)
# 통계 출력
print("최종 통계")
print("="*100)
# 전체 통계
print("전체 결과 (20개 샘플)")
print("-"*50)
total_exact = results["total"]["exact_matches"]
total_contains = results["total"]["contains_answers"]
total_different = results["total"]["different_answers"]
print(f"완전 일치: {total_exact}개 ({total_exact/20*100:.1f}%)")
print(f"정답 포함: {total_contains}개 ({total_contains/20*100:.1f}%)")
print(f"다른 답변: {total_different}개 ({total_different/20*100:.1f}%)")
# Train 데이터 통계
print("\nTRAIN 데이터 결과 (10개 샘플)")
print("-"*50)
train_exact = results["train"]["exact_matches"]
train_contains = results["train"]["contains_answers"]
train_different = results["train"]["different_answers"]
print(f"완전 일치: {train_exact}개 ({train_exact/10*100:.1f}%)")
print(f"정답 포함: {train_contains}개 ({train_contains/10*100:.1f}%)")
print(f"다른 답변: {train_different}개 ({train_different/10*100:.1f}%)")
# Test 데이터 통계
print("\nTEST 데이터 결과 (10개 샘플)")
print("-"*50)
test_exact = results["test"]["exact_matches"]
test_contains = results["test"]["contains_answers"]
test_different = results["test"]["different_answers"]
print(f"완전 일치: {test_exact}개 ({test_exact/10*100:.1f}%)")
print(f"정답 포함: {test_contains}개 ({test_contains/10*100:.1f}%)")
print(f"다른 답변: {test_different}개 ({test_different/10*100:.1f}%)")
print("\n" + "="*100)
# 정확도 계산
total_accuracy_strict = total_exact / 20 * 100
total_accuracy_loose = (total_exact + total_contains) / 20 * 100
train_accuracy_strict = train_exact / 10 * 100
train_accuracy_loose = (train_exact + train_contains) / 10 * 100
test_accuracy_strict = test_exact / 10 * 100
test_accuracy_loose = (test_exact + test_contains) / 10 * 100
print("정확도 요약")
print("-"*100)
print(f"전체 - 엄격한 정확도: {total_accuracy_strict:.1f}% | 관대한 정확도: {total_accuracy_loose:.1f}%")
print(f"TRAIN - 엄격한 정확도: {train_accuracy_strict:.1f}% | 관대한 정확도: {train_accuracy_loose:.1f}%")
print(f"TEST - 엄격한 정확도: {test_accuracy_strict:.1f}% | 관대한 정확도: {test_accuracy_loose:.1f}%")
print("\n" + "="*100)
print("결과 해석:")
print(" 완전 일치: 모델이 정확히 같은 답변을 생성")
print(" 정답 포함: 모델 답변에 정답이 포함됨")
print(" 다른 답변: 정답과 다르지만 맥락상 맞을 수 있음")
print(" TRAIN vs TEST 성능 비교를 통해 과적합 여부 확인 가능")
print("="*100)
# 성능 평가 및 과적합 분석
print("\n성능 분석:")
if total_accuracy_loose >= 70:
print("우수한 성능입니다!")
elif total_accuracy_loose >= 50:
print("괜찮은 성능입니다!")
elif total_accuracy_loose >= 30:
print("개선이 필요합니다.")
else:
print("추가 훈련이 필요합니다.")
# 과적합 분석
performance_gap = train_accuracy_loose - test_accuracy_loose
print(f"\nTrain vs Test 성능 차이: {performance_gap:.1f}%")
if performance_gap > 20:
print("과적합 가능성이 높습니다. 정규화나 데이터 증강을 고려해보세요.")
elif performance_gap > 10:
print("약간의 과적합이 있을 수 있습니다.")
else:
print("과적합이 심하지 않습니다. 일반화 성능이 좋습니다.")
# 메모리 정리
print("\n메모리 정리 중...")
del model
del tokenizer
torch.cuda.empty_cache()
print("메모리 정리 완료!")
Comments ()