간단히 정리한 폴라스(Polars) 사용법
기존에 사용하던 판다스(Pandas)보다 속도가 빠르다는 폴라스(Polars) 사용법을 간단히 정리해봤습니다.
다음 문서를 기반으로 작성되었습니다.
https://docs.pola.rs/user-guide/getting-started/
최초작성 2025. 8. 14
테스트하기 위한 개발 환경으로 miniconda를 사용했습니다.
Visual Studio Code와 Miniconda를 사용한 Python 개발 환경 만들기( Windows, Ubuntu, WSL2)
https://webnautes.kr/visual-studio-codewa-minicondareul-sayonghan-python-gaebal-hwangyeong-mandeulgi-windows-ubuntu-wsl2/
polars 패키지는 다음처럼 설치합니다.
pip install polars
읽기와 쓰기(Reading & writing)
Polars는 일반적인 파일 형식(예: CSV, JSON, Parquet), 클라우드 저장소(S3, Azure Blob, BigQuery) 및 데이터베이스(예: PostgreSQL, MySQL)의 읽기 및 쓰기를 지원합니다.
다음 코드는 데이터프레임을 생성하고 이를 디스크에 저장하고 다시 읽어오는 방법을 보여줍니다.
import polars as pl
import datetime as dt
# 데이터프레임을 생성합니다. 4개의 열로 구성됩니다.
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
# 데이터프레임을 `output.csv`라는 CSV 파일로 저장합니다.
df.write_csv("output.csv")
# CSV 파일을 다시 읽고 화면에 출력합니다.
df_csv = pl.read_csv("output.csv", try_parse_dates=True)
print(df_csv)
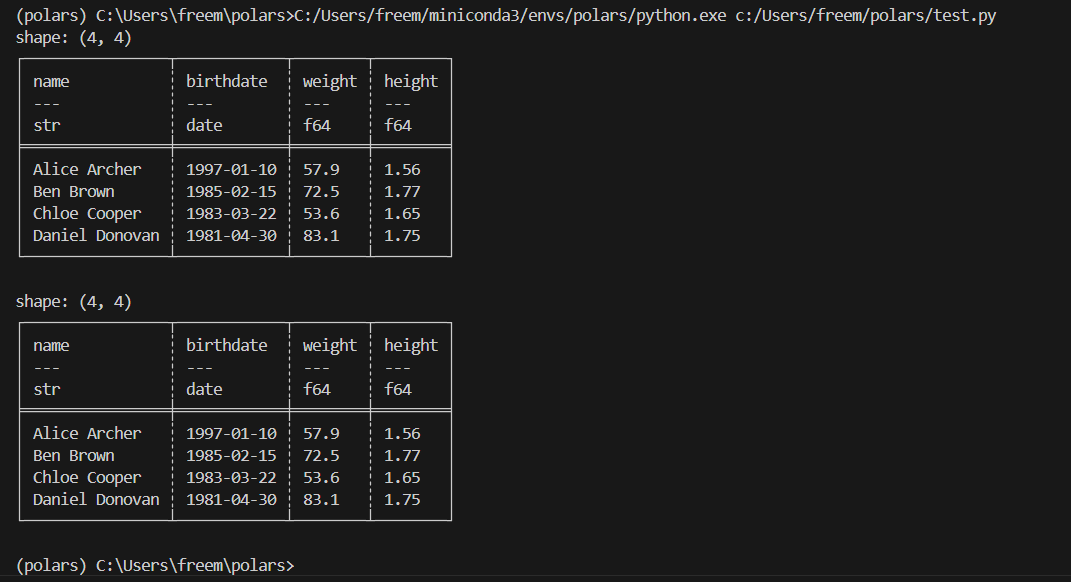
CSV 파일 형식 및 기타 데이터 형식에 대한 추가 예제는 사용자 가이드의 IO 섹션을 참조하세요.
표현식 및 컨텍스트(Expressions and contexts)
표현식(Expressions)은 Polars의 주요 강점 중 하나입니다. 왜냐하면 데이터 변환을 표현하는 모듈형이고 유연한 방법을 제공하기 때문입니다.
다음은 Polars 표현식의 예시입니다:
pl.col("weight") / (pl.col("height") ** 2)
이 표현식은 “weight”라는 이름의 열의 값을 “height” 열의 값의 제곱으로 나누어 사람의 BMI를 계산합니다. 위 코드는 추상적인 계산을 표현합니다: 이 표현식은 Polars의 context 내에서만 결과로 구성된 시리즈로 구체화됩니다.
표현식과 컨텍스트에 대한 자세한 내용은 해당 사용자 가이드 섹션을 참고하세요: [https://docs.pola.rs/user-guide/concepts/expressions-and-contexts/]
select
select는 데이터프레임에서 원하는 열을 선택하여 새로운 데이터프레임을 생성합니다. 이때 컬럼을 조작할 수 있습니다.
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
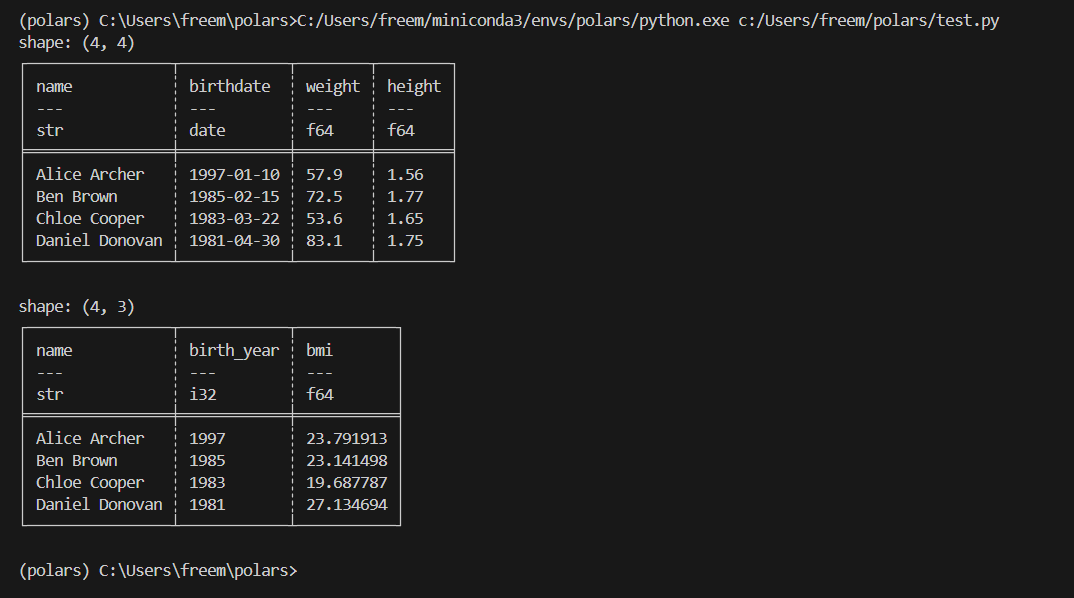
result = df.select(
# 이름 컬럼을 그대로 선택
pl.col("name"),
# 생년월일에서 연도만 추출하고 컬럼명을 'birth_year'로 변경
pl.col("birthdate").dt.year().alias("birth_year"),
# 체중을 키의 제곱으로 나누어 BMI를 계산하고 컬럼명을 'bmi'로 설정
(pl.col("weight") / (pl.col("height") ** 2)).alias("bmi"),
)
print(result)
Polars는 “표현식 확장”이라는 기능을 지원합니다. 이 기능은 하나의 표현식이 여러 표현식을 대신하는 역할을 합니다. 아래 예시에서 우리는 표현식 확장을 사용하여 단일 표현식으로 “weight”와 “height” 열을 한번에 조작합니다. 표현식 확장을 사용할 때 .name.suffix를 사용하여 원본 열 이름에 접미사를 추가할 수 있습니다:
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
result = df.select(
# 이름 컬럼을 그대로 선택
pl.col("name"),
# weight와 height 컬럼에 0.95를 곱하고 소수점 2자리로 반올림한 후, 컬럼명 뒤에 '-5%' 접미사 추가
(pl.col("weight", "height") * 0.95).round(2).name.suffix("-5%"),
)
print(result)
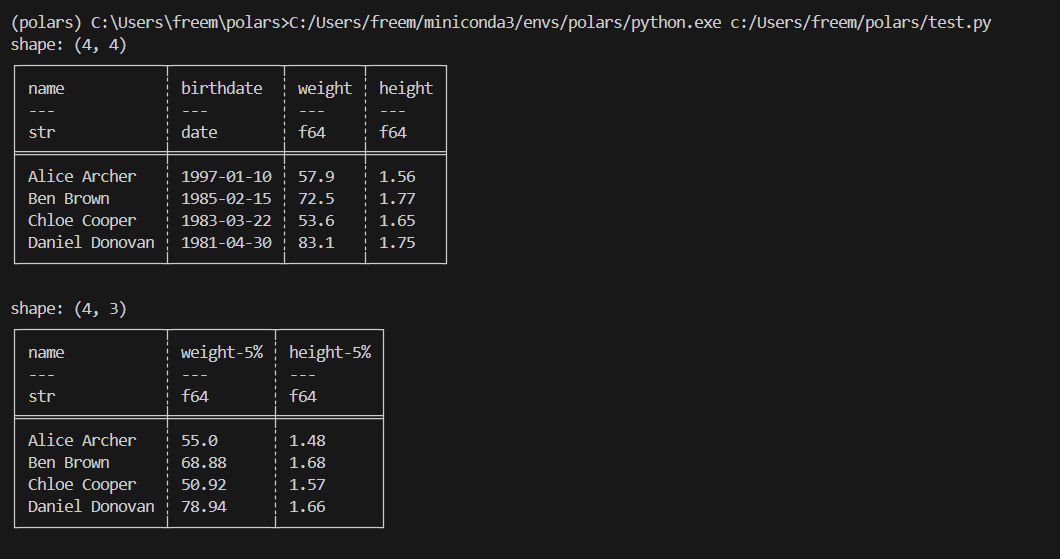
사용자 가이드의 다른 섹션을 확인하여 기본 조작 또는 표현식 확장 시 열 선택에 대해 자세히 알아볼 수 있습니다.
with_columns
데이터프레임에서 열을 선택하여 새로운 데이터프레임을 생성하는 select와 달리 with_columns는 기존 데이터프레임에 새로운 열을 추가합니다.
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
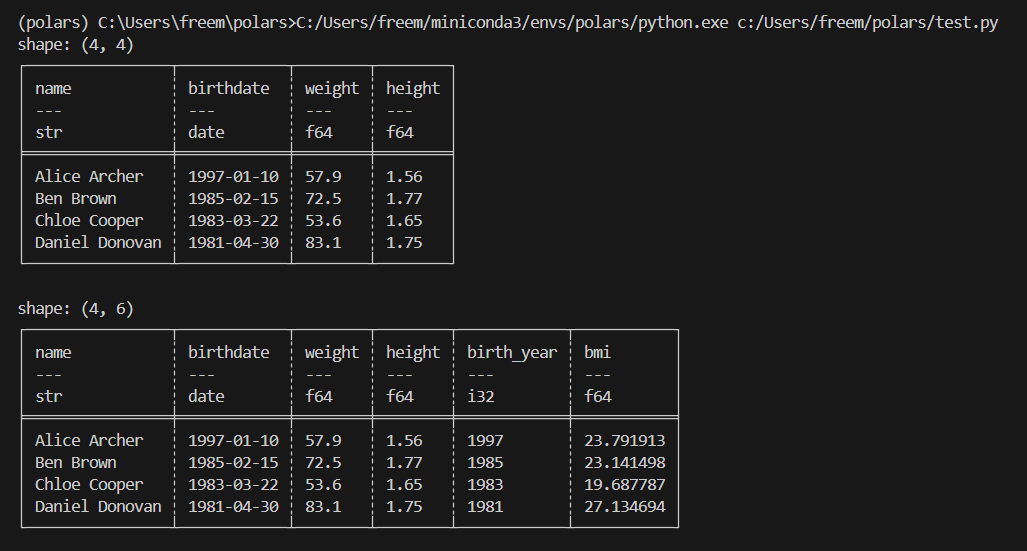
# 새로운 열의 이름을 지정하기 위해 `alias` 메서드 대신 이름 지정 표현식을 사용. select나 group_by에서도 사용가능
result = df.with_columns(
# 생년월일에서 연도만 추출해서 'birth_year' 컬럼 추가
birth_year=pl.col("birthdate").dt.year(),
# 체중을 키의 제곱으로 나누어 BMI를 계산해서 'bmi' 컬럼 추가
bmi=pl.col("weight") / (pl.col("height") ** 2),
)
print(result)
filter
filter는 데이터프레임에서 특정 조건에 맞는 행(데이터)만 걸러내는 기능입니다.
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
# birthdate 컬럼의 생년월일에서 연도를 추출해서 1990년보다 이전에 태어난 사람들만 필터링
result = df.filter(pl.col("birthdate").dt.year() < 1990)
print(result)
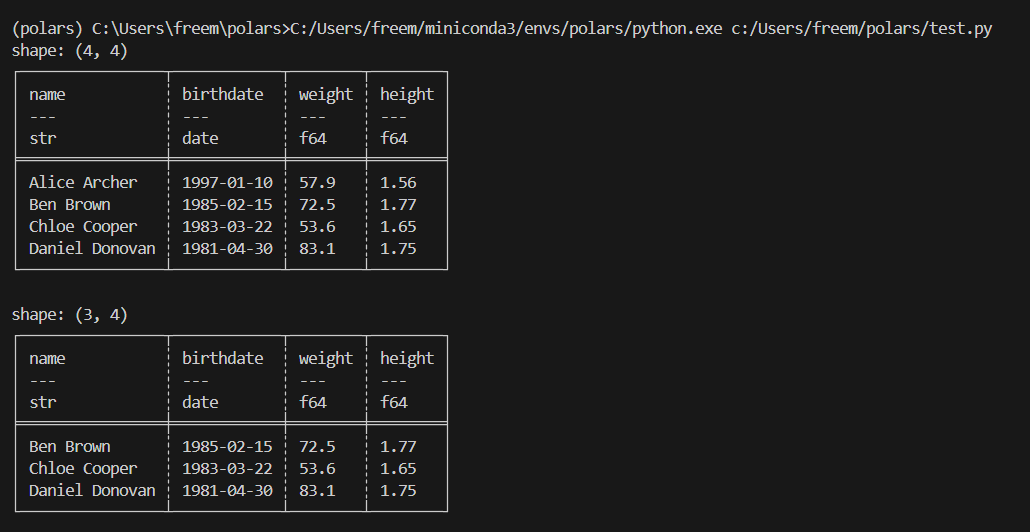
여러 개의 술어 표현식을 별도의 매개변수로 제공할 수 있으며, 이는 모두 &로 연결하는 것보다 더 편리합니다:
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
# 주어진 조건을 모두 만족하는 행(데이터)만 남게됨.
result = df.filter(
# 생년월일이 1982년 12월 31일과 1996년 1월 1일 사이에 있는 사람
pl.col("birthdate").is_between(dt.date(1982, 12, 31), dt.date(1996, 1, 1)),
# 키가 1.7m보다 큰 사람
pl.col("height") > 1.7,
)
print(result)
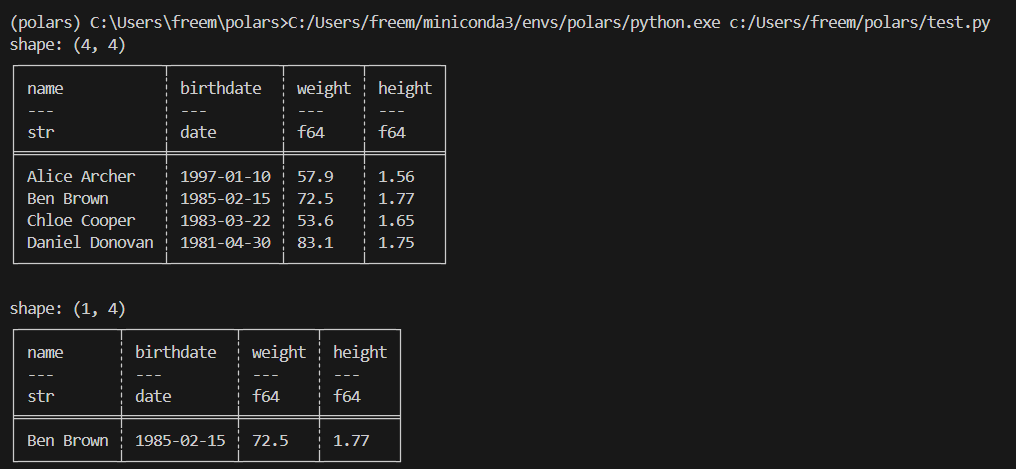
group_by
group_by는 데이터프레임에서 같은 값을 가진 행들을 하나의 그룹으로 묶어서 집계 계산을 수행하는 기능입니다.
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
result = df.group_by(
# 생년월일에서 연도를 추출하고 10년 단위로 묶어서 'decade' 컬럼으로 명명
(pl.col("birthdate").dt.year() // 10 * 10).alias("decade"),
maintain_order=True, # 원본 데이터의 순서를 유지
).len() # 각 그룹의 개수를 계산
print(result)
키워드 인자 maintain_order는 Polars가 결과 그룹을 원본 데이터프레임에 나타나는 순서와 동일하게 표시하도록 강제합니다. 이 옵션은 그룹화 작업을 느리게 만들지만, 예제의 재현성을 보장하기 위해 여기에서 사용됩니다.
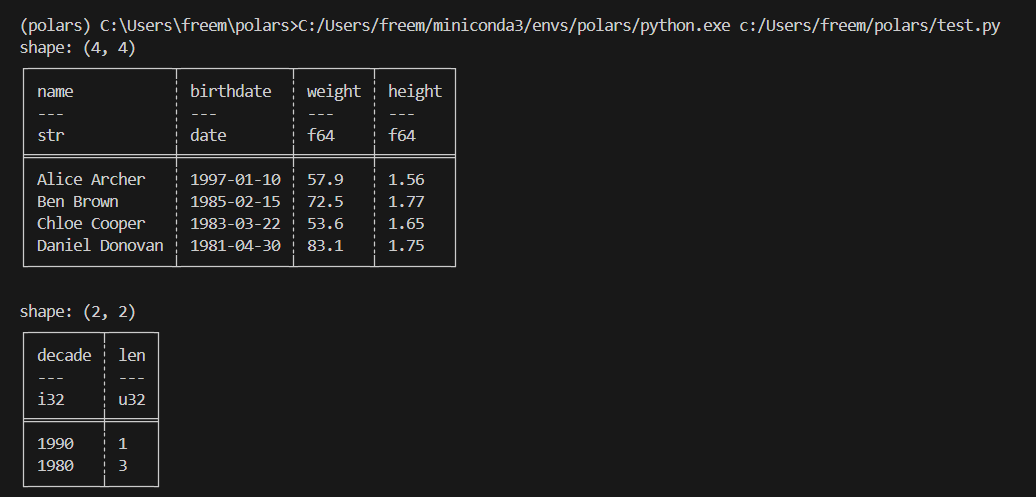
group_by로 그룹을 만든 후에는 agg를 사용해서 각 그룹별로 다양한 통계 계산을 합니다.
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
result = df.group_by(
# 생년월일에서 연도를 추출하고 10년 단위로 묶어서 'decade' 컬럼으로 명명
(pl.col("birthdate").dt.year() // 10 * 10).alias("decade"),
maintain_order=True, # 원본 데이터의 순서를 유지
).agg(
# 각 연령대별 사람 수를 세어서 'sample_size' 컬럼으로 저장
pl.len().alias("sample_size"),
# 각 연령대별 평균 체중을 계산하고 소수점 2자리로 반올림해서 'avg_weight' 컬럼으로 저장
pl.col("weight").mean().round(2).alias("avg_weight"),
# 각 연령대별 최대 키를 찾아서 'tallest' 컬럼으로 저장
pl.col("height").max().alias("tallest"),
)
print(result)
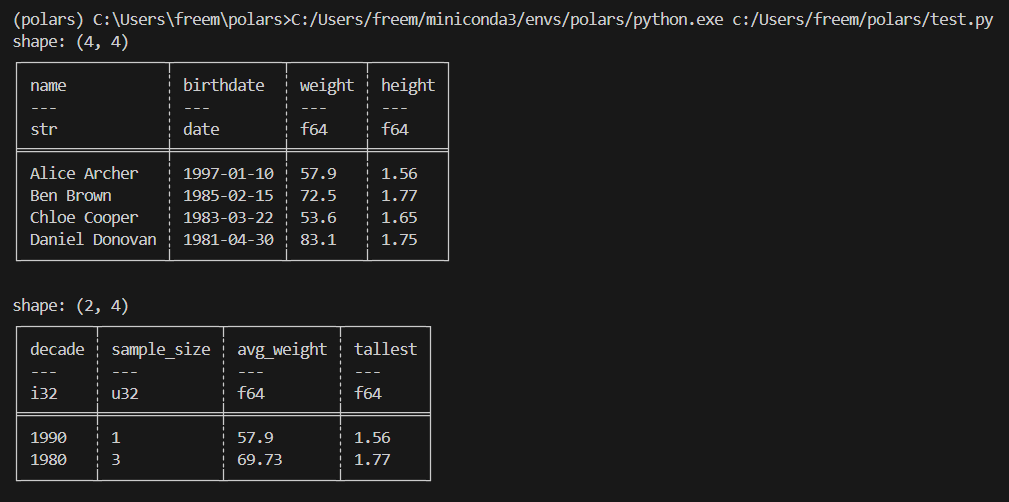
More complex queries
컨텍스트와 그 내부의 표현식은 필요에 따라 연결되어 더 복잡한 쿼리를 생성할 수 있습니다. 아래 예제에서는 지금까지 살펴본 일부 컨텍스트를 결합하여 더 복잡한 쿼리를 생성합니다:
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
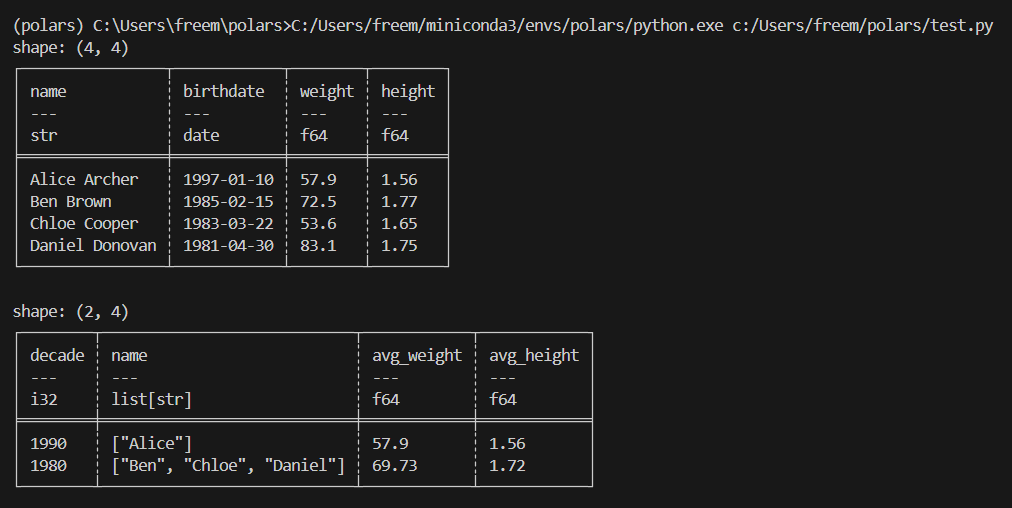
result = (
df.with_columns(
# 생년월일에서 연도를 추출하고 10년 단위로 묶어서 'decade' 컬럼 추가
(pl.col("birthdate").dt.year() // 10 * 10).alias("decade"),
# 이름을 공백으로 나누고 첫 번째 부분만 가져와서 'name' 컬럼을 덮어쓰기 (성만 추출)
pl.col("name").str.split(by=" ").list.first(),
)
.select(
# 'birthdate' 컬럼을 제외하고 나머지 모든 컬럼 선택
pl.all().exclude("birthdate"),
)
.group_by(
pl.col("decade"), # 연령대별로 그룹화
maintain_order=True, # 원본 데이터의 순서를 유지
)
.agg(
# 각 그룹의 모든 이름을 리스트로 수집
pl.col("name"),
# weight와 height의 평균을 계산하고 소수점 2자리로 반올림한 후, 컬럼명 앞에 'avg_' 접두사 추가
pl.col("weight", "height").mean().round(2).name.prefix("avg_"),
)
)
print(result)
데이터프레임 결합(Combining dataframes)
폴라스는 두 개의 데이터프레임을 결합하기 위한 다양한 도구를 제공합니다. 여기에선 결합(join)의 예시와 연결(concatenation)을 살펴봅니다.
데이터프레임 조인(Joining dataframes)
폴라스는 공통 열을 기준으로 두 데이터프레임을 결합하는 다양한 조인 방법을 제공합니다. 조인은 두 개의 별도 테이블에 있는 관련 정보를 하나의 테이블로 합치는 작업입니다.
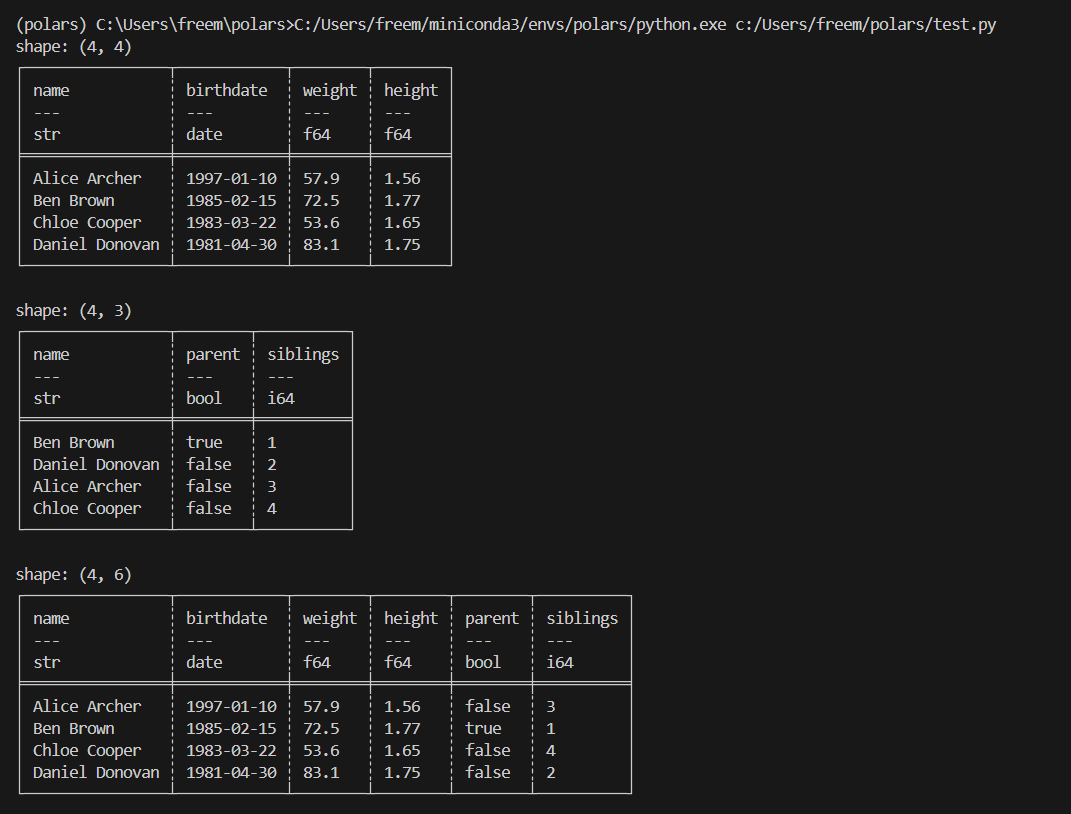
아래 예제는 왼쪽 테이블의 모든 데이터를 유지하면서 오른쪽 테이블에서 일치하는 정보를 가져오는 left join 방법을 보여줍니다:
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
df2 = pl.DataFrame(
{
"name": ["Ben Brown", "Daniel Donovan", "Alice Archer", "Chloe Cooper"],
"parent": [True, False, False, False],
"siblings": [1, 2, 3, 4],
}
)
print(df2)
print()
# df와 df2를 'name' 컬럼을 기준으로 left join하여 결과 출력
print(df.join(df2, on="name", how="left"))
Polars는 다양한 조인 알고리즘을 제공하며, 이에 대한 자세한 내용은 사용자 가이드의 조인 섹션에서 확인할 수 있습니다.
데이터프레임 연결(Concatenating dataframes)
조인은 공통키로 두 테이블을 붙이는 거라면 데이터프레임 연결은 여러 개의 독립적인 데이터프레임을 하나로 붙여서 더 큰 데이터프레임을 만드는 작업입니다.
import polars as pl
import datetime as dt
df = pl.DataFrame(
{
"name": ["Alice Archer", "Ben Brown", "Chloe Cooper", "Daniel Donovan"],
"birthdate": [
dt.date(1997, 1, 10),
dt.date(1985, 2, 15),
dt.date(1983, 3, 22),
dt.date(1981, 4, 30),
],
"weight": [57.9, 72.5, 53.6, 83.1], # (kg)
"height": [1.56, 1.77, 1.65, 1.75], # (m)
}
)
print(df)
print()
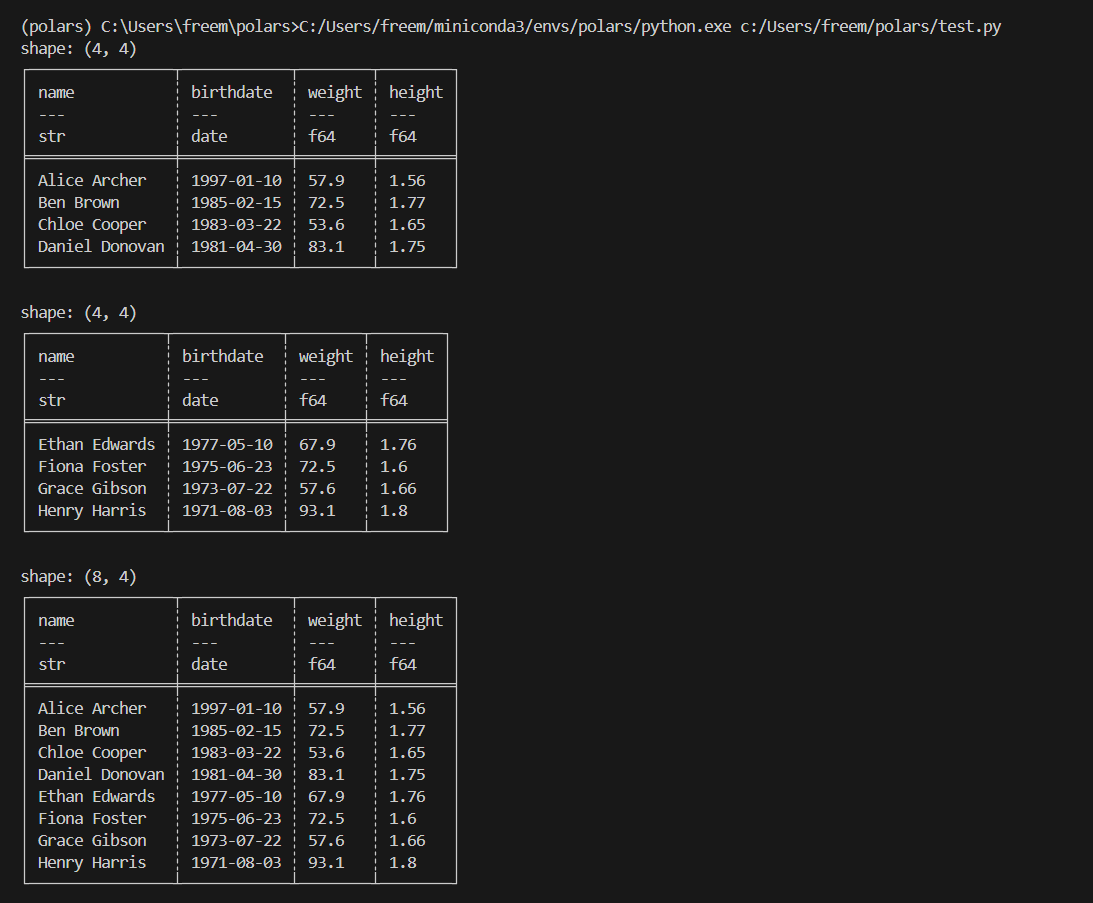
df3 = pl.DataFrame(
{
"name": ["Ethan Edwards", "Fiona Foster", "Grace Gibson", "Henry Harris"],
"birthdate": [
dt.date(1977, 5, 10),
dt.date(1975, 6, 23),
dt.date(1973, 7, 22),
dt.date(1971, 8, 3),
],
"weight": [67.9, 72.5, 57.6, 93.1], # (kg)
"height": [1.76, 1.6, 1.66, 1.8], # (m)
}
)
print(df3)
print()
# df와 df3를 세로로 연결하여 행이 더 많은 데이터프레임을 생성하고 결과 출력
print(pl.concat([df, df3], how="vertical"))
Polars는 수직 및 수평 연결뿐만 아니라 대각선 연결도 제공합니다. 이 기능에 대해 자세히 알아보려면 사용자 가이드의 연결 섹션을 참조하세요.
Comments ()